Explain Activity 1.11 NCERT Science Class 9 Chapter 1 Matter In Our Surroundings
Experiment to demonstrate air is compressible while water and solid are not
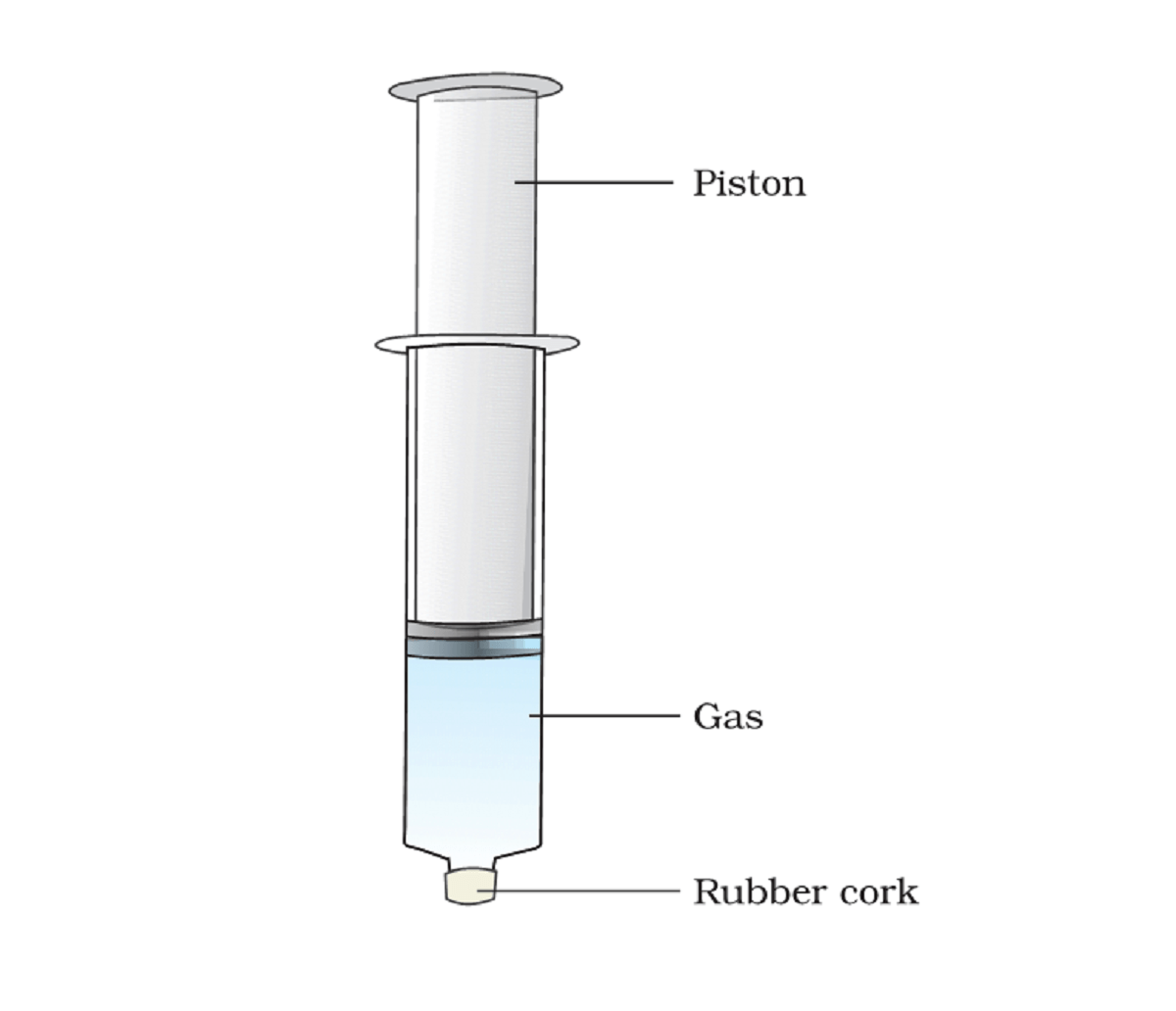
Activity 1.11 wants us to fill three syringes, each with one type of object viz, water, chalk powder, and air and ask us to compress it.
Observation:
With some force, we are able to compress the syringe filled with air while other syringes are completely non-compressible.
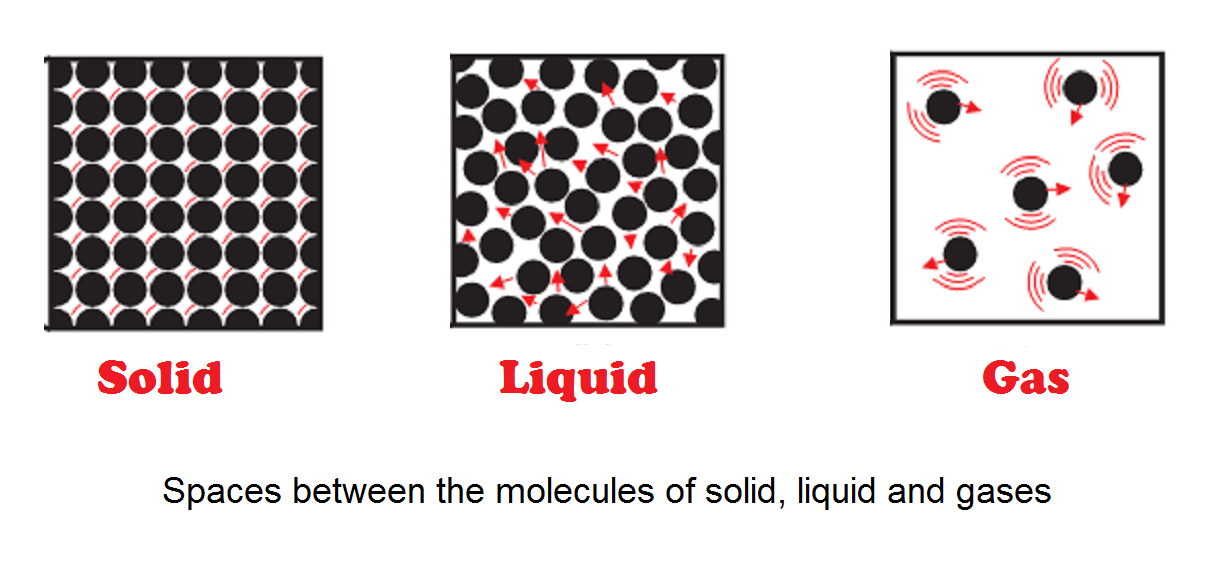
Solid, liquid and gases have a different amount of spaces between their constituent molecules. A solid has the least space between the molecule which does not move; while gases have the largest intermolecular spaces. When we compress a gas its intermolecular space decreases. Since gases have large intermolecular space, we are easily able to compress it with force. While in the case of liquid and solid small intermolecular space makes it completely impossible to compress.
Inference/conclusion:
This experiment demonstrates that gases are compressible while liquids and solids are not.
Next: Experiment to demonstrate the physical state of a matter changes with temperature: Activity 1.12.
See also: Experiment to demonstrate liquid has no shape: Activity 1.10.
Application:
Hydraulic elevator and cranes
Liquids adjust their shape and are non-compressible. Hydraulic machinery uses this property. These machines are like a piston. They push a large surface area while the nozzle is small. S0 a little push result in greater force just like a syringe or pichkari. This tremendous force makes lifting easy. For more details, you can visit this article on hydraulics from Explainthatstuff.com.
Other facts:
- When we push a syringe the pressure energy is converted into heat energy. If we push and pull the syringe vigorously, it becomes hot.
- There is a limit to the compression of gases. Beyond that, the gas starts behaving like a liquid. e.g., Liquid nitrogen. Wikipedia.


This is a very nice app I have actually tryed in byjus but I did not like it but it is very good I understood it very easily actually in byjus when I type a chapter name they give me the answer for some other chapter answers but this app is very good I liked it